I recently came across a tool called GPT detector and I’m confused about how it determines if text is AI-generated. I need to understand its accuracy for an upcoming project and whether it can produce false positives or negatives. Any advice or experiences would be great.
GPT detectors, lol, what a wild ride those are lately. Basically, these tools try to sniff out if text was written by AI (like ChatGPT) or a human by analyzing patterns and statistical quirks. They’ll look at stuff like word predictability, sentence structure, repetitiveness, and sometimes even signature “AI-ese” phrasing, which honestly is getting harder to spot as models improve.
But here’s the kicker: their accuracy ranges from “eh, maybe?” to “haha, no.” If you’re banking on them for anything super important—like hiring, academics, or compliance—just don’t. GPT detectors absolutely throw out false positives (real human gets flagged as a bot, oops) and false negatives (AI-generated stuff passes as human). I’ve even seen instances where classic literature gets flagged as AI just cause it’s written “weirdly” according to today’s patterns.
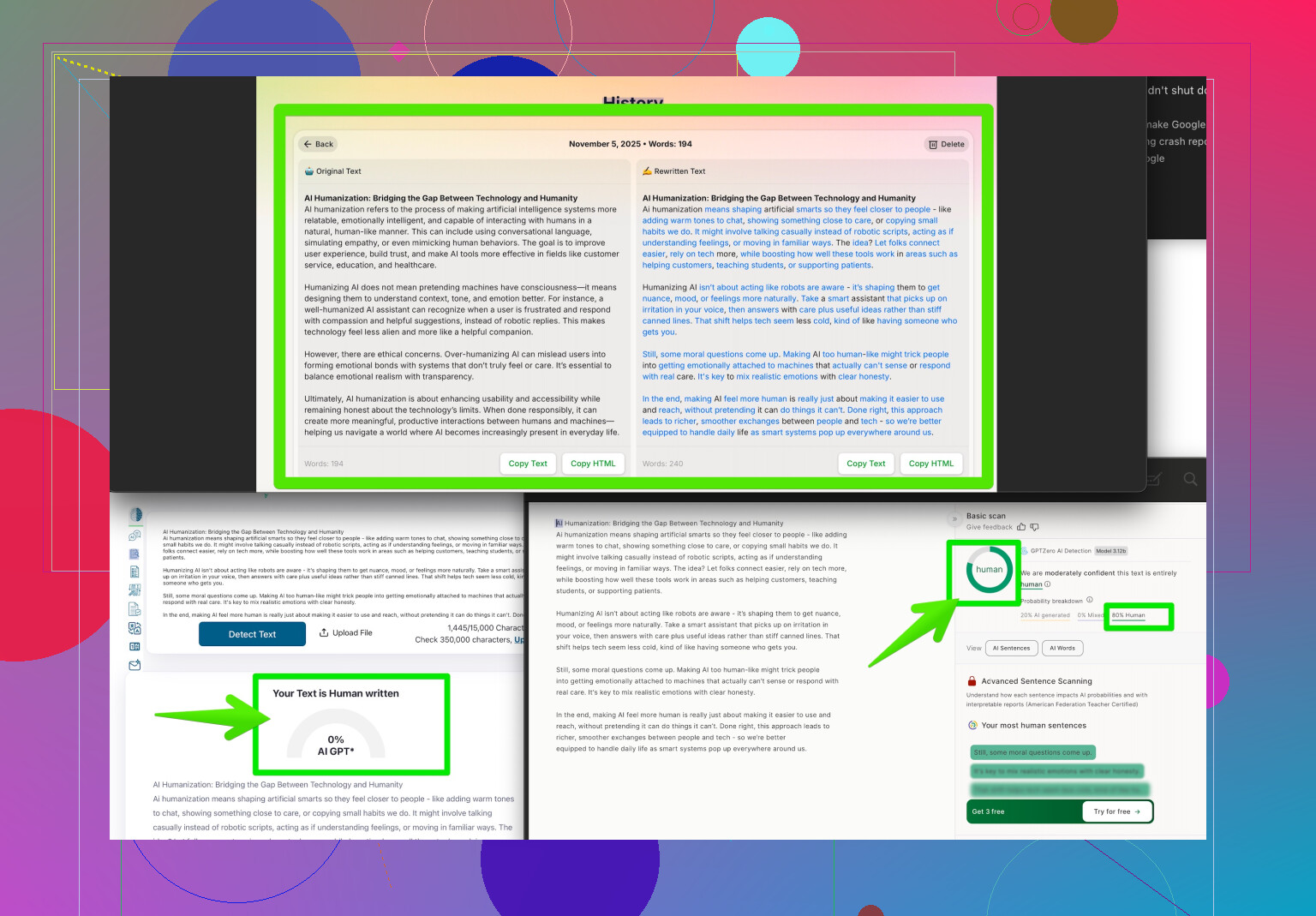
If your project needs to reliably pass these kinds of checks—or you just want to play with AI-generated text without hassle—take a look at making your writing indistinguishable from human with tools like Clever AI Humanizer. That site specializes in tweaking AI content to dodge these detectors, with better results than simple paraphrasers.
Bottom line? Don’t trust detectors 100%. They’re imperfect, context-ignorant, and easily tricked with even minor human edits or a decent humanizing tool. Proceed accordingly.
7 Likes
Honestly, these ‘GPT detectors’ are giving off big polygraph vibes—people want to believe in the magic, but, just like the lie detector, they’re mostly smoke and mirrors. Sure, the ins and outs are a little more technical (shoutout to @sternenwanderer for the nitty-gritty on predictability and statistical quirks)—but the reality? Most current detectors are somewhere between a coin toss and a very judgy English teacher that doesn’t like slang or, for some reason, “clever” writing.
Here’s my take: AI-generated text, especially from newer models, is creeping ever closer to regular human flavor. Even with a few distinctive “AI tells” (repetition, bland transitions, weirdly hedged language), the gap’s shrinking. Detection tools mostly guess based on “what seems likely,” not on solid proof. I’ve seen GPT detectors flag travel blogs, college essays, even text messages from my grandma as “AI,” and I’m pretty sure she’s not a robot… At least, not yet.
Accuracy? Not great. Not for anything important, anyway. Totally possible to get false positives (humans flagged as bots) or false negatives (AIs cruising under the radar). If your project needs to pass these detectors, you’ll probably have to use an AI humanizer—Clever AI Humanizer stands out since it’s tailored to dodge such tools, not just spit out a rewritten version that’s still super generic.
One thing I’d add to the convo is that human intervention (editing text, consciously adding mistakes, idioms, or changing tone) can also fool detectors, but that’s time-consuming. Automated tools save that headache.
If you’re digging for more pro tricks to make your AI-generated content look real, check out these Reddit user secrets for human-like text. Lots of hands-on stuff from people playing this game daily.
Bottom line: Don’t treat GPT detectors as gospel. Use them for giggles or curiosity, not as a hardline truth test for high-stakes stuff. And if you need to outsmart them, go for something specialized like Clever AI Humanizer instead of rolling the dice.
Let’s cut through the hype with a data-driven take: GPT detectors are built on language models trained to spot subtle statistical features—entropy, burstiness, sentence-level perplexity—that differ between machine- and human-written text. It sounds cutting-edge, but the truth is, these features overlap a ton, especially since GPT models (and humans) both produce wide-ranging styles. That means detectors get genuinely confused when you feed them creative, nonstandard, or edited writing—even stuff by classic authors, as others highlighted.
Accuracy? In peer-reviewed benchmarks, most detectors barely crack 70% reliability on mixed datasets. This means if you’re using them as a gatekeeper for hiring, grading, or compliance, you’re playing statistical roulette: plenty of false positives (humans marked as bots) and false negatives (GPT text sliding through), which aligns with what others said. Human editing or simple change-ups in tone trip up detectors, but that’s tedious work if you’re generating a lot of text.
Here’s a curveball: most detectors also struggle with non-native speakers, flagging “imperfect” English as AI. Not ideal if inclusion matters.
If you’re after ways to make AI text more natural and less detectable, Clever AI Humanizer is a legit option—it goes beyond basic synonyms, actually restructuring phrasing for flow and nuance. Pros: it saves time, helps dodge detector traps, and boosts readability. Cons: still possible to get generic output if you don’t tweak settings, and the tool isn’t foolproof if you have super specialized content.
Competitors have similar features, but I’ve found that sticking with purpose-built humanizers like Clever AI Humanizer keeps you one step ahead of most basic detectors (at least, until detection tech levels up… again).
Bottom line: Detectors are useful for curiosity, but not for serious gatekeeping. For projects where detection is a risk, smart humanizing tools are your best bet, just don’t forget to add your own QA for important docs.